Benchmarking ALSSM Backends: numpy, lfilter, jit, and GPU [code910.0]¶
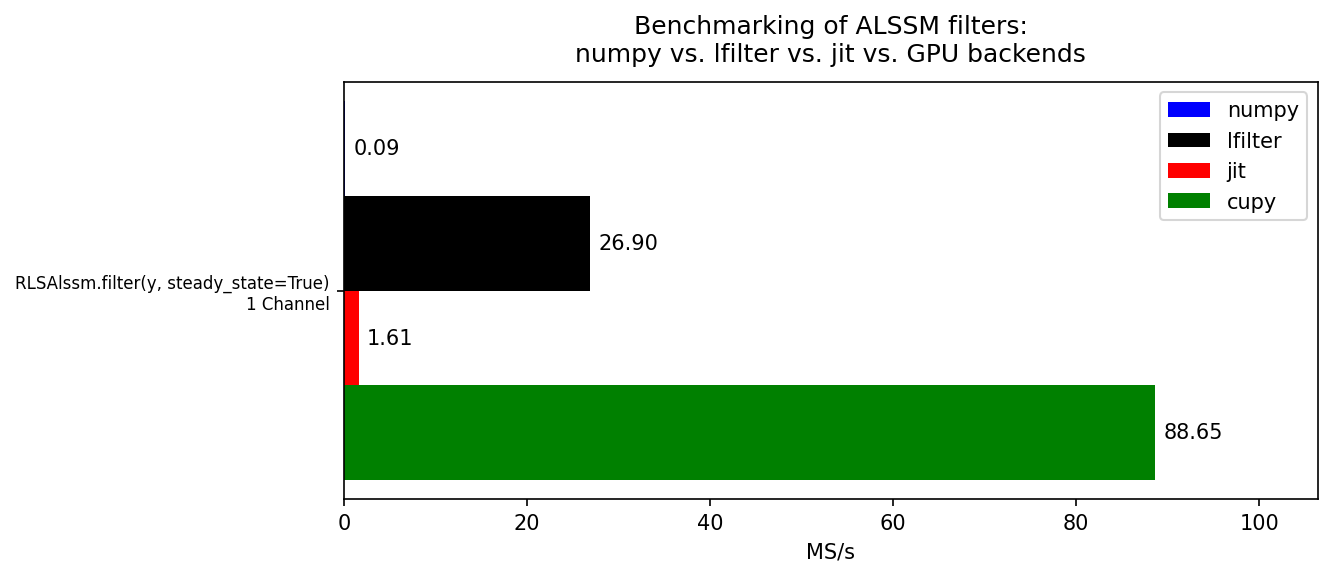
Measures the throughput (in mega-samples per second, MS/s) of the
RLSAlssm filter for the numpy,
lfilter, jit, and cupy backends on a single-channel signal.
The lfilter backend converts the state-space recursion to a cascade of
IIR/FIR transfer functions and uses scipy.signal.lfilter,
which can be significantly faster for long signals when the model order is low.
The jit backend applies Numba Just-In-Time compilation to the state-space
recursion. The cupy backend mirrors the lfilter cascade realization
but runs the IIR cascade on the GPU via
[cupyx.scipy.signal.lfilter][].
Notes on fair GPU timing¶
- CuPy kernel launches are asynchronous, so the device is synchronised around
each timed call (
cp.cuda.Device().synchronize()). - The first GPU call pays one-off allocation/compilation costs; a warm-up call is issued before timing starts.
- The current backend transfers each segment's result back to host once per
filter()call (a device→host copy). For short signals this transfer can dominate; the GPU advantage grows with signal lengthK.
Plot¶
Hardware (locally generated figures)
These figures were generated locally on the hardware listed below and cannot be reproduced on the CI build server.
| Component | Specification |
|---|---|
| GPU | NVIDIA GeForce RTX A2000 |
| CPU | Intel Core i7-12700H |
| RAM | 32 GB |
| OS | Ubuntu 22.04 LTS |
| Date | 2026-06-23 |
Code¶
"""
Benchmarking ALSSM Backends: numpy, lfilter, jit, and GPU [code910.0]
======================================================================
Measures the throughput (in mega-samples per second, MS/s) of the
[`RLSAlssm`][lmlib.statespace.rls.RLSAlssm] filter for the ``numpy``,
``lfilter``, ``jit``, and ``cupy`` backends on a single-channel signal.
The ``lfilter`` backend converts the state-space recursion to a cascade of
IIR/FIR transfer functions and uses [`scipy.signal.lfilter`][scipy.signal.lfilter],
which can be significantly faster for long signals when the model order is low.
The ``jit`` backend applies Numba Just-In-Time compilation to the state-space
recursion. The ``cupy`` backend mirrors the ``lfilter`` cascade realization
but runs the IIR cascade on the GPU via
[`cupyx.scipy.signal.lfilter`][cupyx.scipy.signal.lfilter].
Notes on fair GPU timing
------------------------
* CuPy kernel launches are asynchronous, so the device is synchronised around
each timed call (``cp.cuda.Device().synchronize()``).
* The first GPU call pays one-off allocation/compilation costs; a warm-up call
is issued before timing starts.
* The current backend transfers each segment's result back to host once per
``filter()`` call (a device→host copy). For short signals this transfer can
dominate; the GPU advantage grows with signal length ``K``.
"""
import timeit
import numpy as np
import matplotlib.pyplot as plt
import lmlib as lm
lm.WARNING_NOT_STEADY_STATE = False
n_exe = 5
backends = ['numpy', 'lfilter']
if lm.is_backend_available('jit'):
backends.append('jit')
if lm.is_backend_available('cupy'):
backends.append('cupy')
import cupy as cp
lm.set_gpu_dtype(np.float32)
else:
print("cupy backend not available — benchmarking CPU backends only.")
color_map = {'numpy': 'b', 'lfilter': 'k', 'jit': 'r', 'cupy': 'g'}
K = 1000000
y = np.random.randn(K)
alssm = lm.AlssmPoly(poly_degree=1)
seg_l = lm.Segment(a=-21, b=-1, direction=lm.FW, g=100)
cost = lm.CompositeCost([alssm], [seg_l], F=[[1]])
mspsecs_dict = {}
for backend in backends:
rls = lm.RLSAlssm(cost, backend=backend, calc_kappa=False, calc_W=False, steady_state=True)
if backend == 'cupy':
rls.filter(y)
cp.cuda.Device().synchronize()
def _run():
rls.filter(y)
cp.cuda.Device().synchronize()
proc_time = timeit.timeit(_run, number=n_exe)
else:
rls.filter(y) # warm-up / JIT compile
proc_time = timeit.timeit('rls.filter(y)', globals=globals(), number=n_exe)
mspsec = K * n_exe * 1e-6 / proc_time
mspsecs_dict[backend] = mspsec
print(f"{backend:8s}: {mspsec:8.2f} MS/s")
# ── plot ──────────────────────────────────────────────────────────────────────
labels = ('RLSAlssm.filter(y, steady_state=True)\n1 Channel',)
locs = np.arange(len(labels))
width = 0.25
fig, ax = plt.subplots(figsize=(9, 4))
for i, backend in enumerate(backends):
rect_ = ax.barh(locs + width * i, [mspsecs_dict[backend]], width,
label=backend, color=color_map.get(backend))
ax.bar_label(rect_, fmt="%0.2f", padding=4)
max_val = max(mspsecs_dict.values())
ax.set_xlim(0, max_val * 1.20)
ax.invert_yaxis()
ax.set_xlabel('MS/s')
ax.set_title('Benchmarking of ALSSM filters:\n'
'numpy vs. lfilter vs. jit vs. GPU backends', pad=10)
ax.set_yticks(locs + width * (len(backends) - 1) / 2, labels, fontsize=8)
ax.legend()
fig.tight_layout()
plt.show()