Benchmarking ALSSM ND Backends: numpy, lfilter, jit, and GPU [code910.1]¶
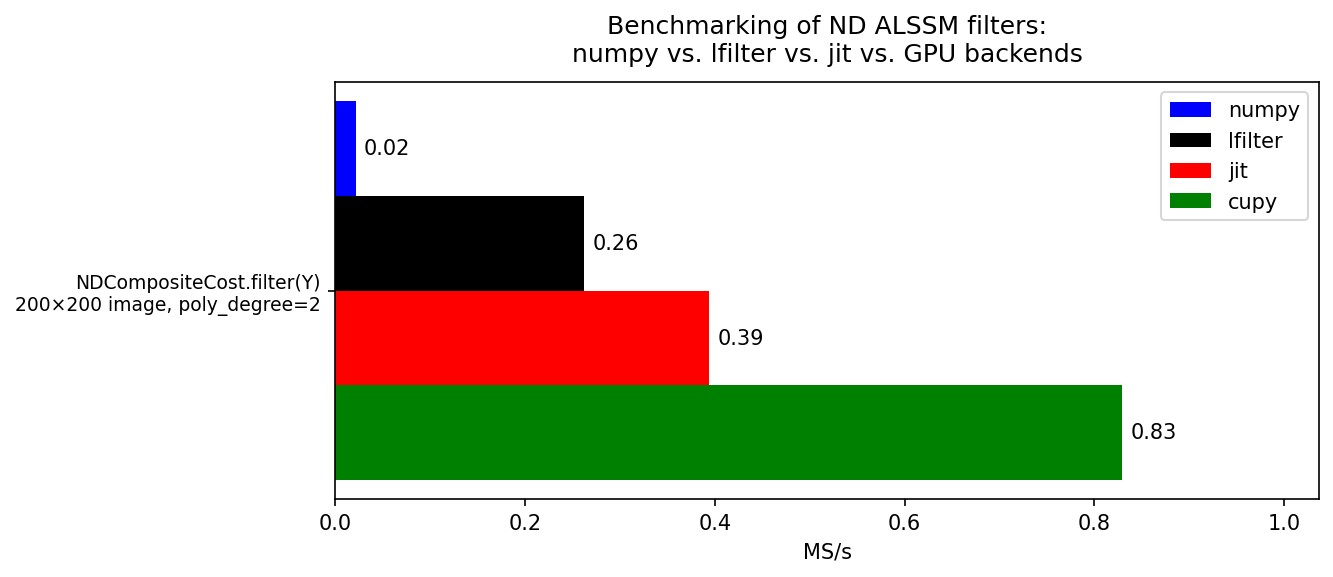
Measures the throughput (in mega-samples per second, MS/s) of the
RLSAlssm filter using an
NDCompositeCost for the numpy,
lfilter, and (if available) jit and cupy backends.
An NDCompositeCost over a 2-D signal (image) is built using
the same separable polynomial basis as in example-ex801.0-Text-Recognition.py.
Each backend processes a (K1 x K2) image and results are reported in mega-samples per second (MS/s = K1 * K2 * n_exe / proc_time * 1e-6).
Notes on fair GPU timing¶
- CuPy kernel launches are asynchronous, so the device is synchronised around
each timed call (
cp.cuda.Device().synchronize()). - The first GPU call pays one-off allocation/compilation costs; a warm-up call is issued before timing starts.
Plot¶
Hardware (locally generated figures)
These figures were generated locally on the hardware listed below and cannot be reproduced on the CI build server.
| Component | Specification |
|---|---|
| GPU | NVIDIA GeForce RTX A2000 |
| CPU | Intel Core i7-12700H |
| RAM | 32 GB |
| OS | Ubuntu 22.04 LTS |
| Date | 2026-06-23 |
Code¶
"""
Benchmarking ALSSM ND Backends: numpy, lfilter, jit, and GPU [code910.1]
=========================================================================
Measures the throughput (in mega-samples per second, MS/s) of the
[`RLSAlssm`][lmlib.statespace.rls.RLSAlssm] filter using an
[`NDCompositeCost`][lmlib.statespace.cost.NDCompositeCost] for the ``numpy``,
``lfilter``, and (if available) ``jit`` and ``cupy`` backends.
An [`NDCompositeCost`][lmlib.statespace.cost.NDCompositeCost] over a 2-D signal (image) is built using
the same separable polynomial basis as in example-ex801.0-Text-Recognition.py.
Each backend processes a (K1 x K2) image and results are reported in
mega-samples per second (MS/s = K1 * K2 * n_exe / proc_time * 1e-6).
Notes on fair GPU timing
------------------------
* CuPy kernel launches are asynchronous, so the device is synchronised around
each timed call (``cp.cuda.Device().synchronize()``).
* The first GPU call pays one-off allocation/compilation costs; a warm-up call
is issued before timing starts.
"""
import timeit
import numpy as np
import matplotlib.pyplot as plt
import lmlib as lm
lm.WARNING_NOT_STEADY_STATE = False
# ---- Signal & model setup --------------------------------------------------
K1 = 200 # image rows
K2 = 200 # image columns
Y = np.random.randn(K1, K2)
n_exe = 2 # number of filter executions per timing measurement
g = 100
l_side = 35
poly_degree = 2
alssm_l = lm.AlssmPolyLegendre(poly_degree=poly_degree, a_seg=-l_side, b_seg=-1)
alssm_r = lm.AlssmPolyLegendre(poly_degree=poly_degree, a_seg=0, b_seg=l_side)
seg_l = lm.Segment(a=-l_side, b=-1, direction=lm.FW, g=g)
seg_r = lm.Segment(a=0, b=l_side, direction=lm.BW, g=g)
F = [[1, 0], [0, 1]]
cost_d1 = lm.CompositeCost([alssm_l, alssm_r], [seg_l, seg_r], F)
cost_d2 = lm.CompositeCost([alssm_l, alssm_r], [seg_l, seg_r], F)
nd_cost = lm.NDCompositeCost([cost_d1, cost_d2])
# ---- Backend selection -----------------------------------------------------
backends = ['numpy', 'lfilter']
if lm.is_backend_available('jit'):
backends.append('jit')
if lm.is_backend_available('cupy'):
backends.append('cupy')
import cupy as cp
lm.set_gpu_dtype(np.float32)
else:
print("cupy backend not available — benchmarking CPU backends only.")
color_map = {'numpy': 'b', 'lfilter': 'k', 'jit': 'r', 'cupy': 'g'}
mspsecs_dict = {}
# ---- Benchmark loop --------------------------------------------------------
for backend in backends:
rls = lm.RLSAlssm(nd_cost, steady_state=True, backend=backend, filter_form='cascade')
if backend == 'cupy':
rls.filter(Y)
cp.cuda.Device().synchronize()
def _run():
rls.filter(Y)
cp.cuda.Device().synchronize()
proc_time = timeit.timeit(_run, number=n_exe)
else:
rls.filter(Y) # warm-up / JIT compile
proc_time = timeit.timeit('rls.filter(Y)', globals=globals(), number=n_exe)
mspsec = K1 * K2 * n_exe * 1e-6 / proc_time
mspsecs_dict[backend] = mspsec
print(f" {backend:8s} {mspsec:.3f} MS/s")
# ---- Plot ------------------------------------------------------------------
labels = (f'NDCompositeCost.filter(Y)\n{K1}×{K2} image, poly_degree={poly_degree}',)
locs = np.arange(len(labels))
width = 0.25
fig, ax = plt.subplots(figsize=(9, 4))
for i, backend in enumerate(backends):
rect_ = ax.barh(locs + width * i, [mspsecs_dict[backend]], width,
label=backend, color=color_map.get(backend))
ax.bar_label(rect_, fmt="%0.2f", padding=4)
max_val = max(mspsecs_dict.values())
ax.set_xlim(0, max_val * 1.25)
ax.invert_yaxis()
ax.set_xlabel('MS/s')
ax.set_title(
'Benchmarking of ND ALSSM filters:\nnumpy vs. lfilter vs. jit vs. GPU backends',
pad=10,
)
ax.set_yticks(locs + width * (len(backends) - 1) / 2, labels, fontsize=9)
ax.legend()
fig.tight_layout()
plt.show()